

ChatGPT是第一个真正意义的人工通用智能
看到标题,很多专家可能马上想来争辩,别急,本文我们一步步推演。
首先订正一个词:AGI, 国外称Artificial General Intelligence, 国内译作通用人工智能General Artificial Intelligence, 看似很小的一个顺序差异,实则谬以千里,大家多读英文几遍仔细体会。
生命是什么
薛定谔在1944年出版的书《What is Life?》中阐述了他对生命的观点,生命是由负熵喂养大的,后来更正为,自由能才是生命的源泉。薛定谔眼里的生命就是一团活生生的自由能,也是普里高津世界里,不断获取自由能的开放的耗散结构。
大脑如何工作
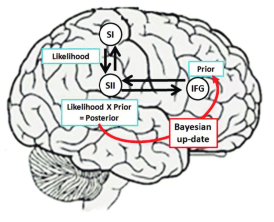
一. 贝叶斯大脑假说
大脑是一个贝叶斯推理机器。大脑不断从世界接收感官信息,并使用这些信息来更新其对世界的内部模型,并对未来事件做预测。大脑的内部模型可以被视为关于世界的先验信仰或假设,感官信息被用于更新这些信仰。
二. 大脑的自由能理论
基于贝叶斯概率理论和生物物理学原理,大脑的主要目标是预测和控制外界的信息,以最大限度地降低不确定性和内部熵。大脑通过不断收集和处理外部信息来构建内部模型,以预测和控制外界。
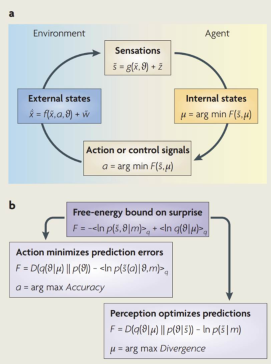
三. 大脑的信息熵
信息熵用来衡量系统不确定性或随机性,这里指大脑关于世界的内部模型的不确定性。大脑的目标是将其内部模型与感官输入之间的预测误差最小化,减少信息熵是减少预测误差的一种方法。通过减少信息熵,大脑可以对世界做出更准确的预测,这等于是使系统的自由能最小化。
ChatGPT 机理
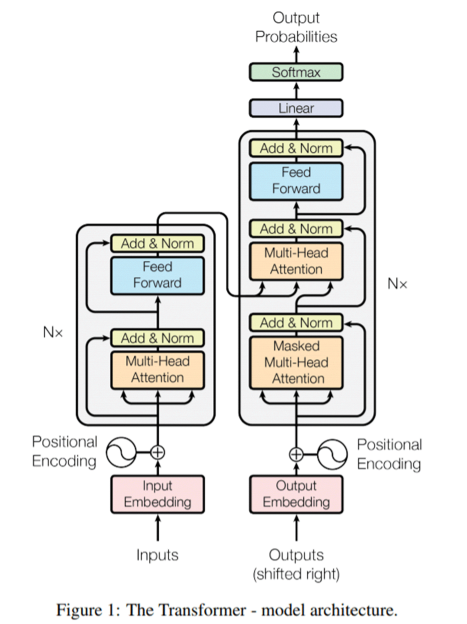
ChatGPT的训练方法是基于Transformer模型,通过学习文本数据的模式来生成文本。Transformer模型的核心是注意力机制,可以在生成文本时,选择性地关注输入的一些部分,从而生成更加符合上下文的文本。
一. Embedding, 形成自己的语言系统
如果将英语看成是26个字母表征的,26个字母张成的空间中,每个单词是一个点,每个句子是一条曲线,每篇文章是一个曲面。
借助Embedding ,GPT 将人类的语言 “编码”成自己的语言,然后通过注意力Attention从中提取各种丰富的知识和结构,加权积累与关联生成自己的语言,然后“编码”回人类的语言。

本质上看,GPT 其实是构建了一个高维的语言体系,可以将自然语言,程序语言,视觉听觉语言,映射(或者叫编码)到这个高维的语言空间中。高维语言空间是概率分布张成的空间。
二. Transformer,提取海量人类知识与相应的知识结构
Transformer是足够强大的特征提取器。仅从知识角度,GPT可以看作是一种以模型参数体现的隐式知识图谱。知识存储在Transformer的模型参数里:多头注意力存储信息的结构(相关强度,信息整合方式等);类似Query/Key/Value结构的FFN存储知识主体。
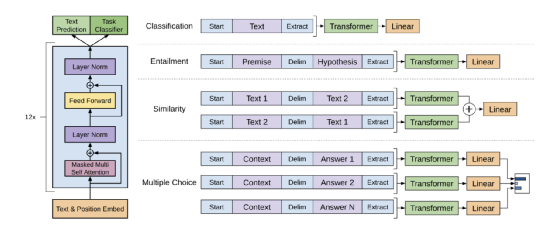
GPT在自己构造的高维语言空间中,通过预训练,记录了人类海量的语言实例,从中提取了无数的结构与关联信息。这个高维的语言空间,加上训练提取的结构与关联信息,可以理解构成了GPT的脑。
从GPT目前的表现看,他应该也已经从这些人类语言蕴含的知识中,学习到了归纳、演绎、对比、类比等基础能力,而这些都是本质的原子思维能力,组合成为推理能力。诸如贝叶斯推理,最优输运,估计都可能已经被提取出来,成为GPT的思维结构的一部分。
三. Pre-train, 海量学习最小化各领域信息熵
预训练 pre-train 阶段,优化目标是最小化交叉熵(cross entropy), 对于GPT 自回归语言模型而言,是看能否正确预测到下一个单词。这里的交叉熵就是信息熵。
研究表明,增加训练数据量,模型参数量,训练时间都会降低测试集上的信息熵. OpenAI 采用的策略是同时增加训练数据量和模型参数, 读得多,记得多。优先增加模型参数,然后才是训练数据量,记忆要好,再多学,再勤学, 与人类学习形式相通。
人们发现,增加多任务的任务数量,增加模型大小,提供思维链提示, 以及增加任务的多样性,都可以提高GPT 泛化能力,包括理解能力,以及推理能力。这些措施都是丰富GPT在某一问题域的信息量,降低其信息熵, 尽力让他见多识广。
上下文学习,通过提供一些例子,具象的表达任务命令。命令是一种更符合人类习惯的抽象任务描述。两者本质上是相通的,GPT从中都是学到了任务的信息熵结构。
上下文中,直接追加辅助推理的提示, 例如“因此”是典型的关系模式选择健,GPT可以借助这些提示选择不同的关系模式。例如“解题思路如下”这样的提示,可以很好激发GPT推理能力,应该缘于训练语料中此类说法很多,可以很好的降低信息熵。
四. 代码训练,获取长程关联与推理能力
目前研究已经证明GPT对知识有强大的记忆能力。而增强GPT推理能力的方法:a) 提供提示语或提示样本 b) 预训练中引入代码样本。ChatGPT强大的推理能力,被认为大概率来自代码参与GPT3.5的预训练。
代码使用计算机语言,是设计完善的特殊语种,结构性强,长程关联,关系明确。可以用微语言结构的概率分布为基底,张成语言空间,程序就是该语言结构空间的点线面体。GPT 可以用自己构建的高维语言空间简单方便的学习代码。
代码其实也可以看成特殊的思维链,训练可以降低信息熵,让信息更可预测。大量这种语言结构示例参与预训练的话,GPT被注入足够的信息量,形成各种复杂关联的模式, 涵盖代码中的知识和知识结构。高质量的代码,可以显著的降低GPT 获取的信息熵,这也是为什么GPT在代码上比自然语言更让人惊艳。
五. Emergent Ability, 涌现能力,相变完成量变到质变
GPT表现,取决于任务类型。a) 知识密集型任务,体现Scaling law, 也就是学的越多,做的越好;b) 推理密集型任务,体现“智慧”,学到一定程度,能力突然爆发。这个好比物理现象,虽然一直维持零度,冰却需要不断吸收热量,最终相变成了水。
信息熵的背景下同样可以出现相变现象。信息熵是衡量系统不确定性或随机性的度量,熵的相变可以被视为系统基础模式或组织的变化。复杂网络系统和量子系统中都可以观察到熵的相变。
在大语言模型领域,模型规模跨越某个阈值,处理任务能力突然性增长,被称为涌现能力(Emergent Ability)。只要针对某个特定问题或任务的相关领域,模型“足够”大,注入足够的信息量,相变就可能发生,即开始涌现。
GPT 构建了海量自然语言和代码的概率分布空间,被注入足够的信息量(等于注入大量负的信息熵),形成各种复杂关联的模式,涵盖自然语言和代码中各种知识与结构。这些知识和结构,体现为概率分布的距离与关系,从而为对比、类比、归纳、演绎等推理步骤提供支撑,也就是“涌现出”这些推理能力。
大胆猜测,GPT甚至可能学习到了在空间里面的贝叶斯概率图和推理,概率分布的比较和迁移基于Wasserstein 距离和最优输运Optimal Transport.(笔者在设法从用户的角度进行检验)。提供足够语料,可以降低概率空间的信息熵到一定阈值,从而对某类任务达成相变。
后ChatGPT 时代
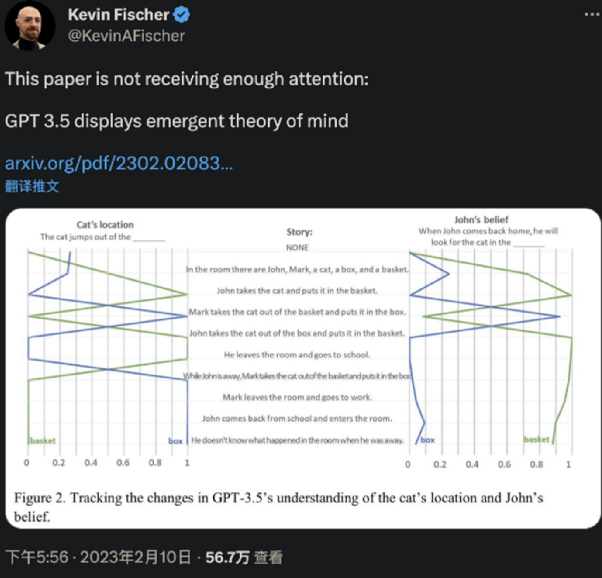
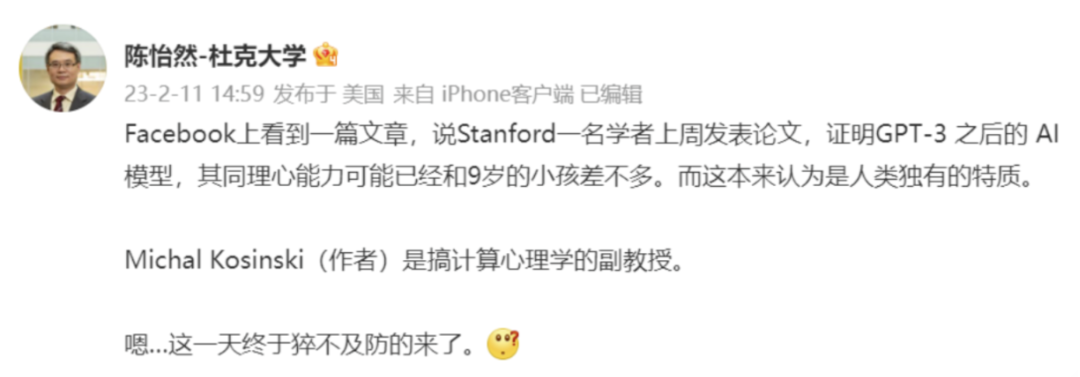
今天来自斯坦福大学的最新研究结论,“原本认为是人类独有的心智理论(Theory of Mind,ToM),已经出现在ChatGPT背后的AI模型上。” 所谓心智理论,就是理解他人或自己心理状态的能力,包括同理心、情绪、意图等。这项研究发现:davinci-002版本的GPT3(ChatGPT由它优化而来),已经可以解决70%的心智理论任务,相当于7岁儿童;至于GPT3.5(davinci-003),也就是ChatGPT的同源模型,更是解决了93%的任务,心智相当于9岁儿童!
ChatGPT 给GPT 注入几万人工标注,有监督学习,虽然不足以修正GPT千亿参数,但是为GPT注入人类偏好,让他听的懂人话、也比较礼貌。这等同于对这个7-9岁儿童的社会教育与激发。
这一天还是到来了,ChatGPT, 人类创造的第一个真正意义上的AGI , 人工通用智能. 后ChatGPT时代,人们应该如何学习与工作?听听ChatGPT的建议:
在 ChatGPT 时代,人们应该采取综合的学习方法,包括接受传统教育,并通过实际应用和独立研究来加深对知识的理解。同时,人们应该不断学习和提高自己的技能,以适应不断变化的环境和技术。此外,利用ChatGPT 等人工智能技术增加学习效率和提高学习质量也是一种很好的途径。
人们可以通过更好地利用 AI 和自动化技术来提高效率和创造力。同时,人们应该加强对人工智能、机器学习和相关领域的学习,以适应未来的工作需求。此外,人们还应该继续关注人类独特的技能,如创造力、社交能力、情感智慧等,以更好地与AI 合作。



 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国