

GPT4技术原理四:重整化群流作为最优输运
本文作为GPT4技术原理探索系列的第四篇,借助哈佛大学Jordan Cotler与 Semon Rezchikov的一篇题目为“重整化群流作为最优输运”的文章( 下文中以RGF-OT指代,https://arxiv.org/abs/2202.11737),介绍一下重整化群与最优输运的内在联系。

论文的作者Jordan Cotler来自哈佛大学研究员协会、哈佛大学黑洞计划和哈佛大学自然基本法中心,研究兴趣包括量子场论、统计力学和机器学习。另一位作者Semon Rezchikov则来自哈佛大学数学系。
两位学者将文章概述为:“我们建立了精确重整化群流的Polchinski方程等价于场相对熵的最优输运梯度流。这提供了一个令人信服的精确重整化群的信息论公式,用最优输运的语言表达。一个显著的结果是,相对熵的正则化实际上是一个RG单调。我们用几个例子计算了这个单调。我们的结果更广泛地适用于其他精确的重整化群流方程,包括广泛使用的特化的Wegner-Morris流。此外,我们的RG最优输运框架允许我们将RG流重新表述为变分问题。这使得新的数值技术成为可能,并在神经网络方法和传统场论的RG流之间建立了系统的联系。”
为更好的解读文章,我们简单回顾一下 “GPT4技术原理二:相变与涌现”中引入的重整化群:重整化群(RG : Renormalization Group) 是研究不同尺度下对称性破缺与重建过程的核心数学手段。借助重整化群这一研究复杂物理系统行为的框架,人们可以在不同尺度上分析系统,并理解随着观察尺度的变化,系统的特性如何变化。通过这种方式,RG提供了一种研究微观细节如何产生较大尺度新涌现特性的方法。
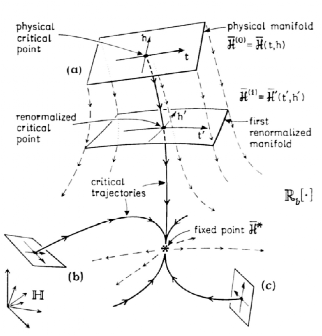
在GPT4技术原理三:重整化群与生成式AI文中我们详述了重整化群流在预训练与生成方面的机理:对一张图像,重整化从细颗粒度到粗颗粒度,逐层提取潜变量Zn, 提取图像中蕴含的各层次的结构;而生成图像的过程就是从粗粒度,对潜变量的高斯概率分布进行采样,重建下一个层次的结构(类似你跟别人描述这个人浓眉大眼)。重整化的群变换Gn 在生成过程中用到 Gn的逆。GPT 和其他大语言模型的使用的Transformer其实就可以类比这些重整化的群变换G。
在”漂亮国的核潜艇与深度学习的内卷“一文中,笔者总结过:玻尔兹曼机践行了重整化群的思想,事实上,在神经网络中引入隐含节点就是尺度重整化。每一次尺度变换后,自由能保持不变。F =-lnZ, 这里Z是配分函数,是一个能量(不同能级上粒子数)的概率分布,Z不变,即能量的概率分布不变。重整化群给出了损失函数,也就是不同层的F自由能的差异,或者说两个能量概率分布的“距离”, 训练就是来最小化这个距离。
这里的距离就是有望实现统一距离度量的“Wasserstein距离”,是由最优输运(OT: Optimal Transport)定义的距离:故事从18世纪末路易十六统治下的法国讲起,蒙日是当时最杰出的科学家,他在研究如何以最小的成本把农场生产的牛奶分配给工厂的奶酪工匠们的高深问题。这个看似简单的问题就是著名的蒙日问题,数学家们用了近200年才完全刻画这个问题。苏联数学和经济学家Kantorovich因对此问题的研究和最优资源匹配的贡献获得了诺贝尔经济学奖。
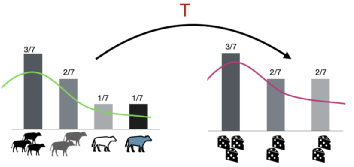
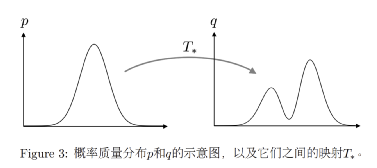
简单理解,OT问题可以抽象成:供应分布 X [x1, x2, x3, x4, …, xn ] 到需求分布 Y [y1, y2, y3, y4, …, ym ] 的最小成本的运输问题 ( cost_ij = xi -> yj ),也就是著名的最优输运(Optimal Transport)问题。从连续的视角看,该问题就是将供应概率分布p(x) 转变成为需求概率分布q(y)。设转移成本(距离函数)为d(x,y),我们得到一个距离定义:


这两个概率分布之间差异的度量就是 Wasserstein距离。它规避了KL散度和JS散度的许多痛点问题。从目前它在各个领域的算法研究中的热度来看,大有一统天下的趋势。如果距离统一这一天到来,玻尔兹曼机,变分推断,重整化群,生成对抗网络,逆向强化学习,还有如今因大模型大热的Transformer,在Wasserstein距离意义上将实现殊途同归。
回到哈佛大学两位学者的RGF-OT这篇文章,他们不仅确定了精确重整化群流的 Polchinski 方程等效于场相对熵的最优输运梯度流,还巧妙的使用最优传输的思想将重整化群转化为变分问题,这种RG的变分形式除了具有理论意义外,还可用于设计计算传统场的重整化群流的神经网络。论文发布时,Semon Rezchikov 连发了二十几条Twitter,提纲挈领的描述了论文中的思想,如下是笔者的概括整理与解读:
文章描述了重整化和熵最小化之间的系统联系,同时为物理学中新的机器学习方法打开了大门。重整化是指当我们观察具有不同精度水平的系统时,参数值随之改变,重整化群流描述了参数对尺度/精度的依赖关系。一个关键的直觉理解是重整化“模糊了”场本身,因而某种意义上等于增加了场的“熵”。论文提出一个关于 RG 的新观点,使得此直觉的主张可以在物理学的层面得到严格论证。关键举措是将 RG 流连接到了最优输运。
两位学者的研究动机来自 Zamolodchikov 的 c 定理,该定理定量的给出了在 RG 流下减少的二维场的物理量。该论文为所有维度的传统场和大量 RG 方案提供了完全不同的基于相对熵的单调描述。基本思想是 RG 流的一个关键方程 --“Polchinski 方程”,在形式上类似于无限维的热力学方程。而我们都知道在热流下熵是不断增加的。因此,寻找场的概率泛函的熵的模拟方法就变得很自然。尽管这个“熵”是严重发散的,论文为其提供了一个自然的而且普遍的正则化。
要获取函数的梯度流,论文非常明确的主张使用来自最优输运(OT) 的 Wasserstein 距离进行度量。最优输运是关于如何最好地将质量从一种分布传输到另一种分布的方法。最优输运主要在有限维环境中得到理解和应用。笔者觉得,尺度变换的每一步,RG Flow 的流向,都将会沿着最优输运的方向进行,也就是物理量的 RG Flow 尺度变换前的概率分布与尺度变换后的概率分布的距离最近的方向,而这就是Wasserstein 距离决定的方向。
将 RG 表述为梯度流意味着可以为各个 RG 步骤提供变分公式——RG 步骤最小化函数。然后可以引入万能的函数逼近器——神经网络——并最小化该函数。论文进一步展示了如何构建相应的有效的神经网络来计算传统场的 RG 流。文章还在几个示例中讨论了 RG 单调的计算,并将 RG 流重新表述为变分问题,从而实现了新的数值技术,并在神经网络方法和传统场的 RG 流之间建立了系统的联系。这种与传统场的普遍而且系统化的联系在该领域尚属首次。而且最令两位学者兴奋的是数值应用的广阔前景,远远超出了论文最初的想法,可以触发有效的数值分析,例如通过变分方法找到场的基态。
表述成RGF-OT文中概念体系,重整化群是量子场论和统计场论中使用的数学框架,用于理解物理系统的有效描述如何随着我们改变观察尺度而变化。它是一种系统地整合高能量自由度以获得低能量有效理论的方法。精确重整化群 (ERG) 是 RG 的一种非微扰方法,它是在改变能量尺度时求解有效作用流的泛函微分方程。论文建立了 ERG 和最优输运之间的联系,提供了用最优输运语言表达的 RG 的新信息理论公式。笔者认为这同时为理论化现有的大模型transformer 建立了理论关联,参见“清熙”微信公众号的相关文章,大模型transformer 在一定约束下,等价于RG 流。
如上文所述,我们知道,最优输运也是一个数学框架,用于确定将给定的质量(概率)分布移动和重新排列为所需质量(概率)分布的最佳方式,给定移动质量跨越指定距离的成本。这个问题可以用两种方式来表述:Monge 表述,其试图找到一种传输函数,使质量从一个分布移动到另一个分布的总成本最小,而且同时满足某些约束;另一种是 Kantorovich 表述,其试图找到一个积极的措施在满足某些约束的同时最小化移动质量的总成本。Wasserstein 距离是概率分布空间上的距离度量,在最优输运中起着核心作用,用于衡量两个概率分布之间的距离。世界的不断演进,都是冥冥中遵循最小化各种代价或成本的方式进行,最优输运某种意义上是自然演化的必然方向和准则。
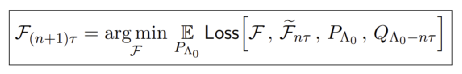
论文中讨论了RG流的变分特征为(近似)计算这种流提供了新的和有趣的数值方法。具体地说,我们将“场”在有限体积域上进行点阵离散; 然后就可以使用标准蒙特卡罗方法从PΛ0[ϕ]进行采样。上文公式告诉我们,这样的采样访问原则上足以解出Fτ , F2τ , ..., Fnτ。假设手头有Fτ , F2τ , ..., Fnτ,在这种情况下,我们希望能够从RG流分布PΛ0−nτ [ϕ】 ≈ (Fnτ∗◦ · · · ◦ F2τ∗◦ Fτ∗)PΛ0[ϕ]中进行采样。而关于如何从这样的分布中采样,文中给出算法类似这样:

如两位学者在论文中的总结,“ RG是量子场论和统计场论的中心思想之一,使我们能够理解当我们调整测量仪器的精度时,物理系统的有效描述是如何变化的。ERG方程是一种特别具有启发性的重整化群的数学表述方法。典型的ERG Polchinski方程,是自然RG格式下RG流的泛函微分方程。论文证明了Polchinski方程可以被重塑为一个相对熵的梯度流。这里的梯度是关于最优输运距离度量(具体来说,是Wasserstein-2度量的一个版本)的泛函泛化。
最优输运理论目前对物理学家来说还不太熟悉,但它是一个丰富的学科,对数学中的偏微分方程和概率论,以及计算机科学中的优化和机器学习产生了深远的影响。我们为物理学家提供这一主题的综述。我们的研究结果表明,最优输运在RG理论中根深蒂固,使我们能够从最优输运中引入强大的工具来分析非摄动RG流。例如,我们精确地解释了RG流产生熵的方式,并阐明了这种方式如何与方案依赖性相互作用。我们发现了一个新的(非微扰)RG单调; 提出了一种新的RG流变分公式,可用于重整化群数值方法的设计。我们的方法适用于比Polchinski的更一般的ERG方程,而且我们的框架提供了对流行ERG方案不直观的特征的优雅解释。“

笔者从意识到GPT4等大模型的惊人的涌现能力时起,阅读了大量的论文与文献,形成了自洽的理论框架用以解释大模型的种种行为和进展。这个系列笔者试着从不同层面,逐步带着读者梳理这一理论框架。随着本系列的推进, 到本文,GPT4等大语言模型的可能的物理原理的脉络应该逐渐清晰起来:
1. Embedding 构建高维空间,用来建模语言文字图像以及音视频,连续变量离散化;
2. 以重整化群流的方式预训练,以在不同尺度上提炼语料数据中的信息概率分布;
3. 重整化群流的每一步流动,都沿着最优输运的成本最低方向进行;
4. 重整化群在不动点附近因新语料带来微扰而发生对称性破缺,滑入不同的相空间;
5. 不同的相空间,对应某种意义上的范畴,或或者可以形象化为语言或信息的结晶;
6. 被Prompt 置于某种context下,大模型内部将限定在相应的高维空间的子空间内推理;
7. 推理是在子空间中的采样,本质是借助动态Bayes推断出原始概率分布,同样遵循最优输运。
从这个理论框架可以推断,对语料数据做embedding后, 通过对其做profiling,然后可以构建 RG 的数学公式,推导出其流动的方向,并计算可能的不动点,从而借助新语料,对不动点做微扰,促进其进入更有序的相空间,实现可控的可预测的涌现产生。另一方面,基于对相空间的内部探测,研究其模型结构,进而可以指导动态Bayes推理更贴切的采样概率分布,增强生成的效果。
在此时点,笔者觉得可以做些实验,按照上述思路修改transformer, 做预训练,探查相空间结构,验证控制涌现的可行性,验证推理生成的改善效果。不知道是不是有大佬可以赞助几台8块GPU的服务器,作为大模型训练环境用于此实验,不胜感激!
作者:王庆法 麻省理工学院物理系学者,数据领域专家,首席数据官联盟专家组成员




 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国