

大模型是人类终结者还是新的小白鼠
人们倾向于好莱坞似的讨论技术问题这几周,媒体被“人工智能教父” 辛顿(Geoffrey Hinton)的故事所吸引,他离开谷歌,为了更自由地谈论人工智能对人类构成的威胁。辛顿的重点是人工智能正处于变得比人类更聪明的风口,会具备能力欺骗和操纵人类听从它的命令。在接受《卫报》采访时,辛顿说:“我之所以不那么乐观,是因为我不知道任何更聪明的东西被不太聪明的东西控制的例子。你需要想象比我们更聪明的东西,就像我们比青蛙更聪明一样。说'好吧,不要把他们连接到互联网'很好,但只要他们在和我们说话,他们就可以让我们做事。”
谷歌DeepMind首席执行官Demis Hassabis也大胆预测,人类水平的人工智能(AI)可能在几年内实现。碳基生命会变成硅基生命的启动加载器?这是非常有吸引力的故事,对辛顿等权威的关注以及对于大模型原理的未知,让人们会倾向于好莱坞似的讨论技术问题。 “恐惧”来自对大模型涌现能力的未知笔者从OpenAI 开放ChatGPT不久就开始一直试用,被其能力所惊艳的同时,也在尝试从各种维度探索和理解其背后的机理。笔者猜测辛顿的“恐惧”主要来自对大模型“涌现”能力的未知。如“涌现:21 世纪科学的统一主题”一文中所述“事实上,我们生活在一个涌现的宇宙中,在这个宇宙中,即使不是不可能,也很难确定任何现有的有趣科学问题或研究,任何社会或经济行为,不是涌现的。”涌现普遍存在,科学家们也正在积极探索各个领域的“涌现”行为,所以个人觉得不必悲观,人类终将理解和掌握涌现,特别是当下,人类亲自制造了大模型的涌现,可控可研究,对人类理解宇宙涌现行为或许是个巨大的契机。
人类亲自制造的大模型可控关于大模型的可控,微软今天恰逢其时地放出了最新的APO论文(Automatic Prompt Optimization with "Gradient Descent" and Beam Search, https://arxiv.org/abs/2305.03495):大型语言模型(LLM)作为通用代理已经表现出了令人印象深刻的性能,但是它们的能力仍然高度依赖于手写的提示,而这些提示是通过繁重的试错工作完成的。我们提出了一个简单的非参数化的解决方案,自动提示优化(APO) ,它受到数字梯度下降法的启发,假定能够访问训练数据和 LLM API,自动改进提示。该算法使用小批量数据来检视当前提示的自然语言“梯度”。然后通过在梯度的相反语义方向上编辑提示,将梯度“传播”到提示中。这些梯度下降法步骤是由定向搜索和强制选择程序指导的,这显著提高了算法效率。三个基准 NLP 任务的初步结果以及 LLM 越狱检测的新问题表明,APO通过使用数据将模糊的任务描述重写为更精确的注释指令,可以优于以前的提示编辑技术,并将初始提示的性能提高高达31% 。

刚刚招募的提示工程师马上就要失业了,通过这种简单通用的提示优化算法,可以自动改进 LLM 的提示,显著减少花费在手动研究提示方法上的时间和精力。进一步表明大模型完全可以控制,而且是用AI来调控AI。人类区别于其他物种的最大特性是会使用“工具”,这一点似乎LLM也会(例如调用API),不过人们可以在使用“工具”前面,加上“创造性地”。
人类亲自制造的大模型亦可研究(一)可控的同时,人们也在用先进的技术手段扫描大模型的“大脑”,窥见他的神经元回路。也就是在今天,OpenAI 公布了他们采用新工具解释语言模型行为的研究进展: 语言模型变得更强大,部署更广泛,但我们不了解它们是如何工作的。最近的工作在理解少量回路和有限的行为方面取得了进展,但要完全理解语言模型,我们需要分析数百万个神经元。本文将自动化应用于扩展可解释性技术到大型语言模型中所有神经元的问题。我们希望基于这种自动化解释性的方法,将使我们能够在部署前全面审核模型的安全性。OpenAI 的工具利用设置将模型分解为多个部分。首先,该工具通过正在评估的模型运行文本序列,并等待特定神经元频繁“激活”的情况。接下来,这些高度活跃的神经元被展示给GPT-4 并生成解释。为了确定解释的准确性,该工具为 GPT-4 提供了文本序列,并让它预测或模拟神经元的行为方式。然后将模拟神经元的行为与实际神经元的行为进行比较。

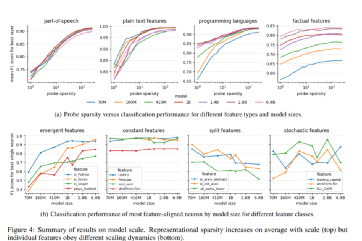
人类亲自制造的大模型亦可研究(二)这个领域突然被关注或许跟OpenAI的主导地位有关。无独有偶,几天前笔者就看到来自麻省理工学院、哈佛大学和美国东北大学的研究团队提出了稀疏探测,这是一种旨在识别与特定特征相关的 LLM 神经元的技术或概念,并有助于理解高级人类可解释的特征如何在此类模型的神经元激活中表示。论文参见Finding Neurons in a Haystack: Case Studies with Sparse Probinghttps://arxiv.org/pdf/2305.01610.pdf。
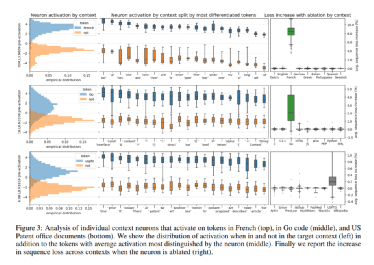
在他们的实证研究中,该团队使用自回归transformer LLM,针对 k 个神经元的一系列值训练探针,并报告了它们的分类性能。他们将主要发现总结如下:1.LLM 的神经元内有大量可解释的结构,稀疏探测是定位此类神经元(即使处于叠加状态)的有效方法,但需要仔细使用和后续分析才能得出严格的结论。2.许多早期层神经元处于叠加状态,其中特征表示为多语义神经元的稀疏线性组合,每个神经元都会激活大量不相关的 n-gram 和局部模式。此外,根据权重统计和玩具模型的见解,我们得出结论,前 25% 的全连接层比其余层使用更多的叠加。3.更高层次的上下文和语言特征(例如,is_python_code)似乎是由单语义神经元编码的,主要在中间层,尽管关于单语义的结论性陈述在方法论上仍遥不可及。4.随着模型规模的增加,表示稀疏性平均增加,但不同的特征服从不同的动态:一些具有专用神经元的特征随着规模出现,其他分裂成具有规模的更细粒度的特征,许多保持不变或随机出现。
AI 物理学将可以解释大模型的原理在“万引大神: 机器学习不存在了”文中,笔者提到:微软总部研究院机器学习理论组负责人、万引大神Sebastien Bubeck宣称传统机器学习已经不存在了,他和他的团队全面转向 AI 物理学。他说:问题在于我们不是在模仿人类的学习,我们真正试图模仿的是一些类似于进化的东西。这是一种非常不同的风格。我认为我们在机器学习中引入的所有工具在GPT-4的光芒下几乎无用且不相关,因为这是一个新领域。我们尝试研究的方法是尝试理解“涌现现象”,还有另一个领域长期以来一直在研究“涌现现象”,即我们试图研究非常复杂的粒子相互作用的系统,以及导致某些涌现行为的系统。大神提出的建议是:让我们研究人工智能的物理学或者通用人工智能的物理学,因为从某种意义上讲,我们现在真正看到的是这种通用智能。那么,研究通用人工智能的物理学意味着什么?它的意思是,让我们试着借鉴物理学家过去几个世纪用来理解现实的方法论。
“ChatGPT是第一个真正意义的人工通用智能”开始,笔者就尝试用物理的方法解释大模型行为:借助Embedding ,GPT 将人类的语言 “编码”成自己的语言,然后通过注意力Attention从中提取各种丰富的知识和结构,加权积累与关联生成自己的语言,然后“编码”回人类的语言。GPT在自己构造的高维语言空间中,通过预训练,记录了人类海量的语言实例,借助transformer从中提取了无数的结构与关联信息。这个高维的语言空间,加上训练提取的结构与关联信息,可以理解构成了GPT的脑。GPT 构建了海量自然语言和代码的概率分布空间,被注入足够的信息量(等于注入大量负的信息熵),形成各种复杂关联的模式,涵盖自然语言和代码中各种知识与结构。这些知识和结构,体现为概率分布的距离与关系,从而为对比、类比、归纳、演绎等推理步骤提供支撑,也就是“涌现出”这些推理能力。相变、涌现以及对称性破缺物理学早有研究笔者接下来也探讨了“相变与涌现以及对称性破缺”:相变也可以被视为一个临界点(Critical Point),系统的行为在此临界点处会发生突变。在这个临界点上,温度或压力的微小变化可以导致系统性质的巨大改变。这是因为系统处于两个相之间的边界上,小的扰动可以推动它落入其中一个相或另一个相。相变可能导致出乎意料的涌现(emergent) 现象。理解相变可以帮助我们更好地理解和预测复杂系统中的这些突然变化,以便更好的理解和掌握涌现现象。相变往往伴随着新对称性或对称性破缺的出现,这可以揭示系统涌现行为的深层次原理。没有预训练的Transformer是一张各向对称的白纸,也就是其语言空间的密度函数ρ是均匀的。这个语言空间的密度函数决定了系统的信息熵,如果我们仍然把 ρ 表示成向量 η,则信息熵可以表示为F(η).随着语料不断被 emdedding 同时基于注意力机制 transform到这个语言空间,空间的密度ρ/η发生改变,信息熵 F(η)随着改变,引发语言空间对称性破缺与重建。这个过程可能会在局部区域不同尺度下持续的进行。一旦触及临界点,对称性破缺引发相变,大模型就会在某些领域、不同长度上下文表现出各种神奇的涌现能力。也就是语言空间中,出现了局部的”学习语言需要相变“中提到的语言结晶(笔者第一次提出,展示了人类的创造性?)。
来自斯坦福学者的质疑不久前,斯坦福学者对大模型涌现提出了异议“别太迷信大模型涌现能力,那是度量选择的结果”。百家争鸣,越辩越明。笔者第一时间拜读了他们的论文,发现一个有待商榷的基础问题:首先论文没有讨论“少样本学习”或“上下文学习”或GPT4,但个人觉得不是重点,重点是论文作者选择的这个线性指标“Token Edit Distance”并不适合用来衡量大模型的语义能力。Token Edit Distance的局限性明显,打个比方,冰变成水,你衡量水分子的距离或温度,看不出物质宏观形态的变化。
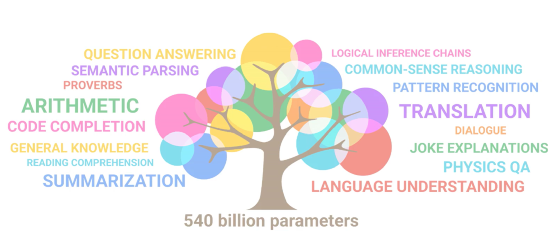
毛毛虫身上没有任何东西可以告诉你它将成为一只蝴蝶,形象深刻的描述了涌现的神奇。所以测量毛毛虫是否涌现,要宏观观测它真的变成了蝴蝶。“大型语言模型的涌现能力”一文提到的大模型的涌现,如上面这颗智慧树,是实打实对LLM客观能力通过人类观测得到的结论:随着LLMs的扩展,它们达到了一系列关键的规模,这些规模突然“解锁”了新的能力。LLMs并没有直接训练这些能力,它们出现在快速且不可预测的方式中,就好像从空气中涌现一样。这些涌现的能力包括执行算术、回答问题、概括段落等等,LLMs通过观察自然语言而学会了这些能力。第一性原理决定大模型不再是炼金术对于当今世界上最锐意创新的大佬埃隆马斯克来说,“第一性原理”的思考方式是用物理学的角度看待世界的方法,也就是说一层层剥开事物的表象,看到里面的本质,然后再从本质一层层往上走。他用最质朴的语言解释了“统计力学”这一第一性原理的思维模式,从微观到宏观,从部分到部分间的关联再到整体。

“Transformer的物理原理”文中,作者就是从这种典型的统计力学视角和思维模式,在物理上为transformer找到了理论解释:原型Transformer模块的神经网络架构蓝图可以从经典统计力学中熟悉的物理自旋系统的结构中导出。更具体地说,我们认为Transformer模块的正向传递,可映射为矢量自旋模型中的计算磁化,作为对输入数据的响应。我们将Transformer想象成可微自旋系统的集合,其行为可以通过训练来塑造。通过从不相干的、统计力学的角度缩小和接近transformer,我们获得了transformer的物理直觉,当我们把自己局限在在纷繁变化的显式神经网络架构时,这种直觉似乎很难获得。将transformer模块视为伪装的自旋模型不仅可以作为近似计算磁化的不同方法,统一架构变化,而且还可以阐释transformer在深度学习中的经验性质的成功。伊辛模型 Ising Model 是用来解释铁磁系统相变的一个简单模型,这样就不难理解大模型中的相变了,从此大模型不再是炼金术,该量子的量子,该涌现的涌现。
总结:如上文笔者所说,科学家们正在积极探索各个领域的“涌现”行为,所以个人觉得不必悲观,人类终将理解和掌握涌现,特别是当下,人类亲自制造了大模型的涌现,可控可研究,对人类理解宇宙涌现行为或许是个巨大的契机。用好大模型这个新的小白鼠,可以从语言的、物理的、数学的、涌现的、演化的、理论的、实验的不同角度,多做各种深度探索。人类的科学理论,从地心说到日心说到现在的“宇宙心说”,其实都是对人类所处的大宏观物理系统的盲人摸象。我们的人工智能科学家们,发明了众多的先进的学习算法,玻尔兹曼机,变分推断,生成对抗网络,逆向强化学习,直到当今如日中天的GPT,都曾经激发了人们对通用人工智能的遐想:AI 有了自己的思维,人类迭代出了新物种。但即使面对如三体人这样先进的新物种,人类依然可以依靠罗辑来拯救。
作者:王庆法 麻省理工学院物理系学者,数据领域专家,首席数据官联盟专家组成员



 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国