

现代社会,人类需要跟肿瘤、糖尿病、心血管疾病等日益流行的复杂疾病持续斗争,原有药品已无法完全满足市场需求,新药研发势在必行。然而,传统的药物发现过程耗时长、投资大,如果能主动在过去药物和放弃使用的化合物中筛选新的药物和治疗目标,显然能显著节省研发成本、提升研发效率。
药物重定位 (Drug Repositioning),即「老药新用」,是一种经过 FDA 批准的、将现有治疗方法应用于新型疾病过程的药物研发方法。例如,西地那非最初用于治疗胸痛,后来发现它是一种 PDE5 (phosphodiesterase type 5 inhibitor) 抑制剂,这使得西地那非在市场上大受欢迎。
由于具有降低药物风险、缩短临床评估周期、低成本和高效性等优势,对现有药物进行重定位已经成为目前行业研究的热点。随着深度学习的快速发展,图卷积网络 (GCN) 已被广泛应用于药物重定位任务。然而,现有的基于 GCN 的方法在深度集成节点特征和拓扑结构方面存在局限性。针对于此,来自中南大学的研究人员在 Bioinformatics 发表了题为「Drug repositioning with adaptive graph convolutional networks 」的论文。
该研究提出了一种名为 AdaDR 的自适应 GCN 方法,通过深度集成节点特征和拓扑结构来进行药物重定位。与传统的图卷积网络不同,AdaDR 通过自适应图卷积操作来模拟它们之间的交互信息,从而增强了模型的表达能力。
具体而言,AdaDR 同时从节点特征和拓扑结构中提取嵌入,并利用注意力机制 (attention mechanism) 学习嵌入的自适应重要性权重。
实验结果表明,AdaDR 在药物重定位方面的性能优于多个基准方法。此外,在案例研究中,还提供了用于发现新的药物-疾病关联的探索性分析。
研究亮点:
* 该研究提出了一种自适应图卷积网络框架,用于药物重定位任务,在拓扑结构和特征空间上执行图卷积操作
* 考虑到拓扑结构和特征之间的差异,该研究采用注意力机制对其进行充分融合,以区分对模型结果的贡献
* 本研究提出的模型在药物重定位任务中具备实用性,有助于降低药物研发失败的风险
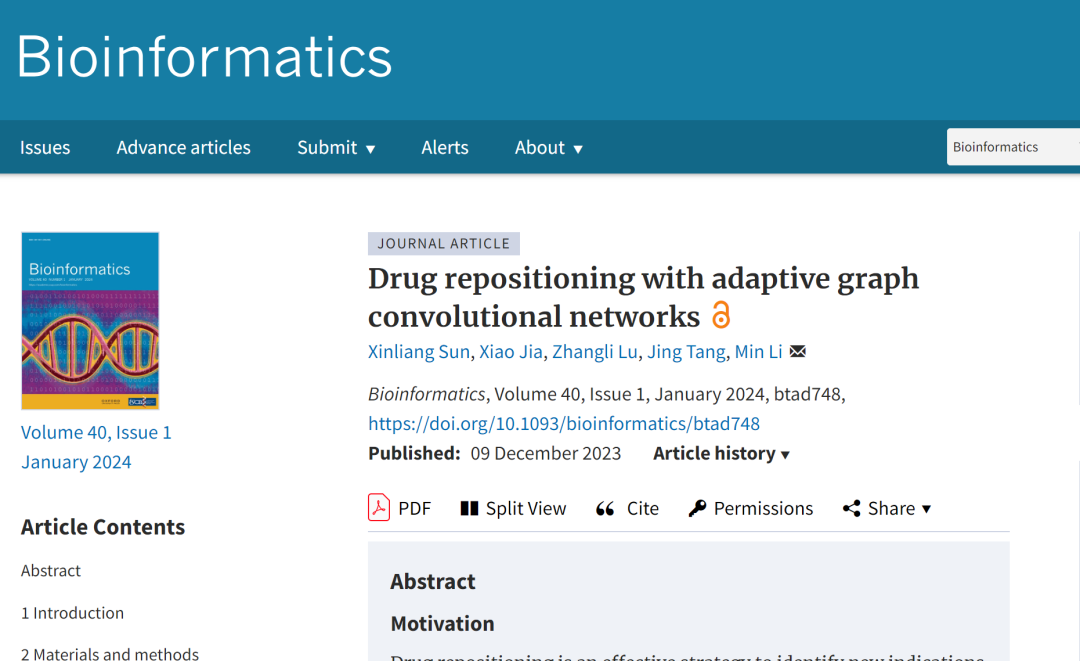
数据集:利用四大基准数据集
为了全面评估所提出模型的性能,该研究利用了 4 个广泛应用于药物重定位任务的基准数据集,分别为 Gdataset, Cdataset, Ldataset 和 LRSSL。
* Gdataset:被视为黄金标准数据集,包括了来自 DrugBank 的 593 种药物,以及 OMIM 数据库中列出的 313 种疾病之间的 1,933 个已证实的药物-疾病关联。
* Cdataset:包含 663 种药物、409 种疾病和 2,352 个相互作用的药物-疾病关联。
* Ldataset:由 CTD 数据集编制而成,包括了 269 种药物和 598 种疾病之间的 18,416 个关联。
* LRSSL:包含了涉及 763 种药物和 681 种疾病的 3,051 个经验证的药物-疾病关联。
与此同时,为了构建药物/疾病特征图,该研究还利用了药物和疾病的相似性特征。数据集统计如下表所示:
四个基准数据集的统计
模型架构:新型自适应 GCNs 框架 AdaDR
本研究提出的 AdaDR 模型框架主要包括三个组成部分。如下图所示:
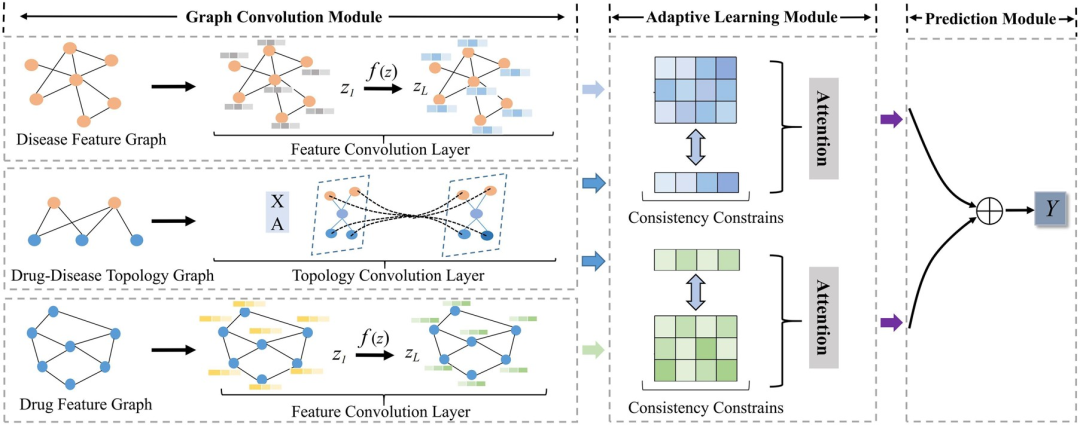
AdaDR 整体框架由三部分组成
* 图卷积模块 (Graph Convolution Module):包含特征卷积层和拓扑卷积层,用于表示特征空间和拓扑空间中的药物/疾病嵌入 (drug/disease embeddings)。
* 自适应学习模块 (Adaptive Learning Module):利用注意机制区分获取的嵌入 (embeddings) 的重要性。在此模块中,使用一致性约束条件 (consistency constraint) 提取特征和拓扑空间之间的共同语义信息。
* 预测模块 (Prediction Module):将嵌入连接在一起作为输出,来预测结果。
研究结果:AdaDR 在药物重定位方面的性能优于多个基准方法
整体而言,AdaDR 作为一种新型模型,能够显著提高药物重定位任务的性能。
首先是在交叉验证中的表现:本研究对 AdaDR 和其他模型进行了 10 次十折交叉验证 (10-fold cross-validation),并计算了结果的平均值和标准偏差。
根据结果,由于 AdaDR 具备特征整合能力,其在 10 次十折交叉验证中,获得的四个数据集的最终平均结果优于所有比较方法。
例如,在 Gdataset、Cdataset、LRSSL 和 Ldataset 四个基准数据集上,该研究的结果分别比次优方法 DRHGCN 的 AUPRC (area under the precision-recall) 高出 9.8%、9.1%、9.1% 和 7.1%,充分展示了新方法的有效性。
接着是在预测新药物潜在适应症能力方面:本研究进行了一项新实验,评估了 AdaDR 预测新药物潜在适应症的能力。
与其他 7 种方法相比,AdaDR 实现了最佳性能(下图中蓝色柱状图代表 AdaDR )。就 AUROC (area under the receiver operating characteristic curve) 而言,如下图 (a) 所示,AdaDR 实现了 0.948 的 AUROC 值,优于其他方法。同时,如下图 (b) 所示,AdaDR 实现了 0.393 的 AUPRC,高于所有其他方法。
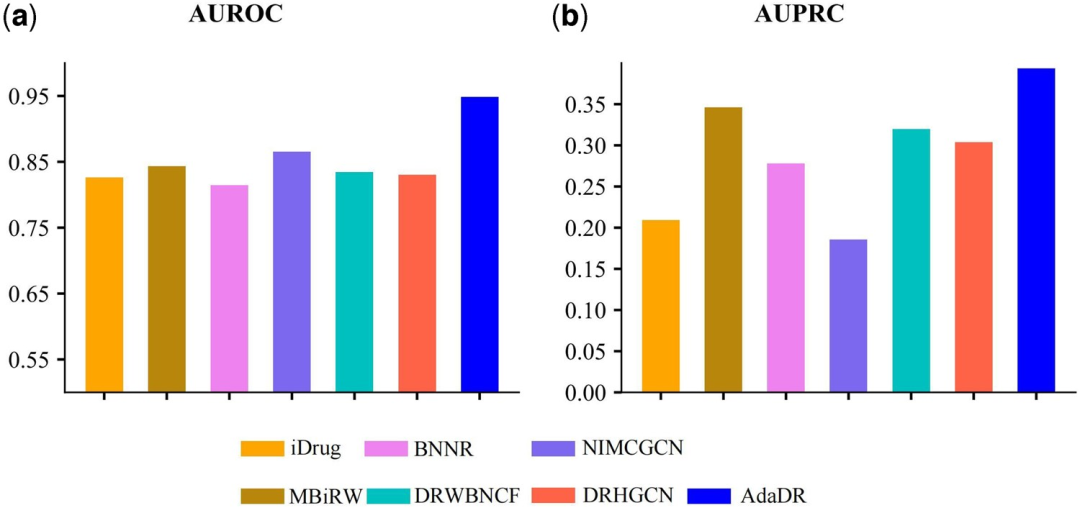
各种方法在 Gdataset 上预测新药物潜在疾病的性能
(a) 应用 AdaDR 和其他竞争方法获得的预测结果的 AUROC。
(b) 应用 AdaDR 和其他竞争方法获得的预测结果的 AUPRC。
值得一提的是,为了进一步验证了 AdaDR 的性能,研究团队还将 AdaDR 应用于预测阿尔茨海默病 (AD) 和乳腺癌 (BRCA) 的候选药物中。
其中,阿尔兹海默症是一种逐渐发展的神经退行性疾病,目前尚无有效药物。乳腺癌是一种乳腺上皮细胞在多种致癌因素作用下失控增殖的现象。尽管目前已经有多种治疗乳腺癌的药物,如紫杉醇、卡铂等,但更多的药物选择可能会提供更好的治疗选择。下表报告了具有证据支持的候选药物:
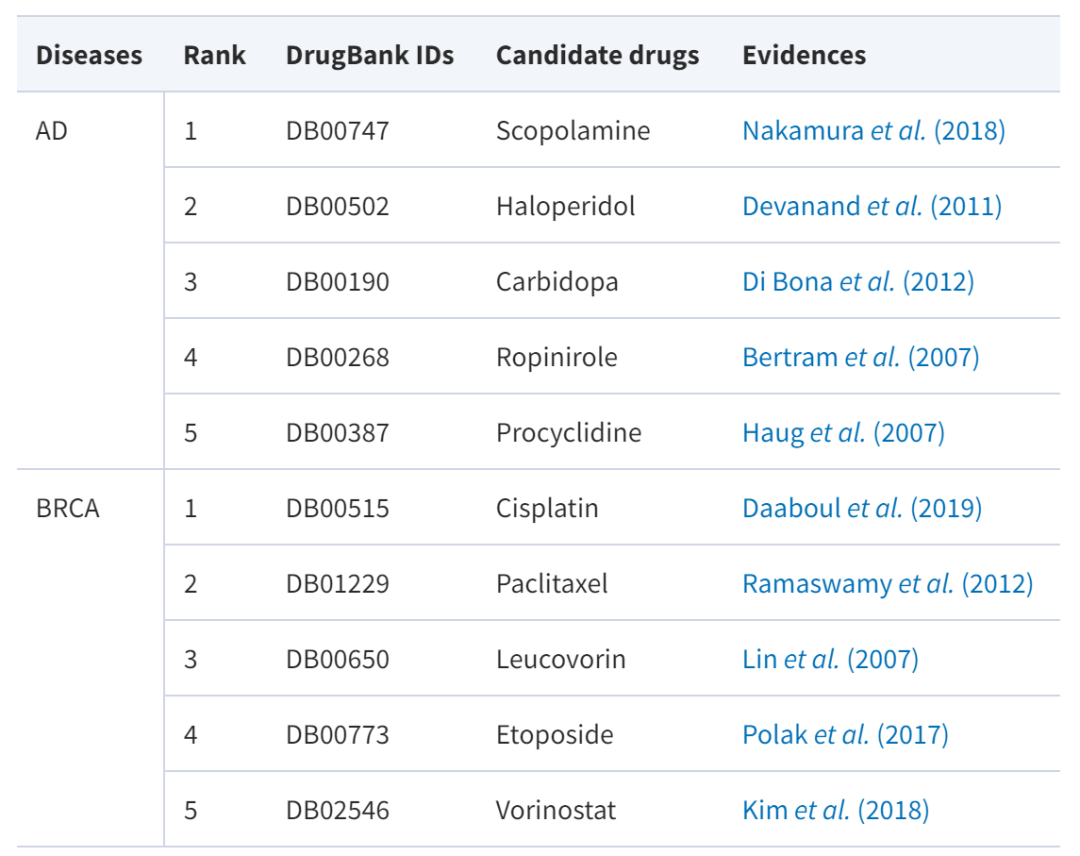
AdaDR 预测分数排名
可以看到,在 AdaDR 预测得分排名前五的药物中,已经有许多通过权威来源和文献验证的证据 (成功率 100%)。此外,该研究的模型可以产生可解释的结果。以紫杉醇为例,模型预测其可以治疗乳腺癌。这确实得到了权威来源和文献的支持。
有趣的是,研究人员发现多西他赛出现在其训练集中。而紫杉醇和多西他赛是具有相同紫杉醇核心的相似分子。这反映了新模型可以利用药物相似性信息进行有意义的预测。
医药研发投资回报率持续下降,药物重定位或成破局关键
当今,药企正处于前所未有的变革之中。新冠疫情大流行和随之而来的经济衰退,使得药企面临着一系列挑战和不确定性,创新回报成为每一家药企关注的重中之重。
尽管生物制药公司在过去 10 年中为创新进行了大量研发投资,但同期回报率却大幅下降。德勤健康解决方案中心 (Deloitte Centre for Health Solutions) 发布的《2019 医药创新回报率评价》显示,2019 年医药行业研发的投资回报率处于 2010 年以来最低水平,仅为 1.8%。从十份报告显示的数据来看,此前十年来,制药公司的研发投资回报率一直处于下降趋势。
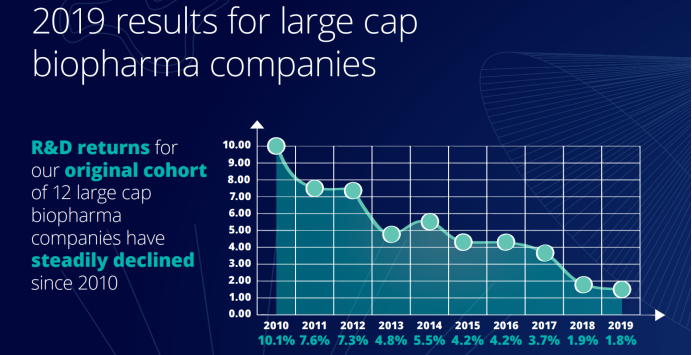
2019 年医药行业研发投资回报率
不仅如此,每款新药上市后的顶峰销售额也从 2018 年的 4.07 亿美元下降至 2019 年的 3.76亿美元,首次跌破 4 亿美元,还不到 2010 年的 8.16 亿美元的一半。与 2010 年相比,上市一款新药的成本增长了 67%,从 2010 年的 11.88 亿美元增至 2019 年的 19.81亿美元。顶峰销售额的下降与上市新药平均成本的增加形成了鲜明的对比,这表明制药公司在研发过程中花费的时间比以往都要长。
而重新定位的药物可以节省将药物推向市场所需的早期成本和时间,从而加快了从基础研究工作到临床治疗的过渡。据业内人士透露,一款新药从开始研发到获批上市,必须要经过体外,临床前动物,临床 Ⅰ、Ⅱ、Ⅲ 期等一系列研究,10 到 15 年是很正常的时间,花费至少要 10 亿美元。与之相比,一些调查结果显示,重新定位药物成本平均只有 3 亿美元,进入市场大约需要 6.5 年。
药物重定位主要包括基于机器学习的方法、大数据挖掘定位的方法和基于活体定位的方法。与基于活体方法相比,基于机器学习和大数据挖掘的药物再定位技术具有速度快、成本低等优点,已成为一项潜在的强大技术。
《基于机器学习和大数据挖掘的药物重定位算法综述》一文中介绍了近年来计算药物重定位的研究进展。
其中,基于传统机器学习算法的方法,首先将药物与副作用信息、药物化学结构信息和疾病与基因的相关信息进行整合,然后通过特征提取和特征选择得到训练数据,进而选择相关机器学习算法进行训练,最后利用训练好的算法模型得到药物重定位结果。
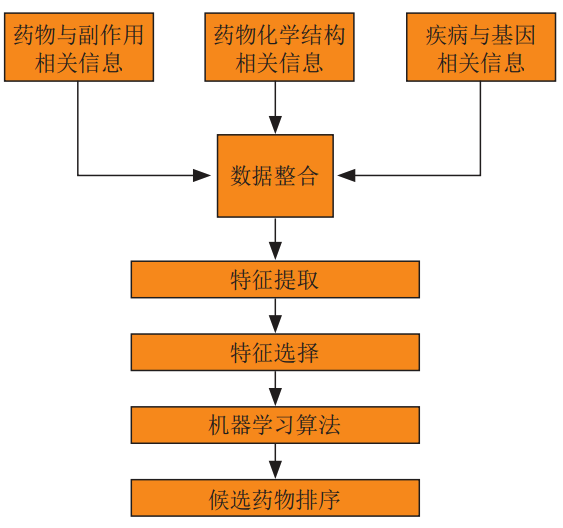
基于机器学习的药物重定位模型
在基于深度学习的方法中,有研究人员将深度神经网络与其他多种机器学习方法在药物研发的多个方面进行系统比较,结果表明,深度学习的表现优于传统机器学习算法。
在基于网络相似性推理方法中,华东科技大学的研究团队提出了一种基于网络的推理 (NBI) 方法,该方法仅使用药物-靶标二分网络拓扑相似性来推断已知药物的新靶标。
随着大数据挖掘技术的发展,基于机器学习和大数据挖掘算法的药物重定位将为疾病的治疗提供更多更有效的方法,已经成为生物医学研究关注的焦点。有理由相信,理性推理和计算模型将在未来的药物重定位过程中发挥重要作用。



 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国