

又是一年高考放榜时,当千万考生和家长或欣喜或紧张地填写志愿时——有一群特殊的“考生”,也刚刚结束了一场前所未有的高考之旅。
2024年,9款顶尖AI大模型参加了这场“特别的高考”,它们分别来自OpenAI、百度、阿里、腾讯、字节跳动等知名公司,以及百川智能、智谱AI、月之暗面科技和MiniMax等新锐企业。

人工智能挑战高考
那么,在人类智力的试金石——高考面前,人工智能大模型的表现如何?是轻松考上北大清华,还是考大专都够呛?
考试结果显示,大模型在文科领域的表现尤为出色,有的甚至可以远超一本线;然而在理科领域表现不尽如人意,数学和理综科目的分数普遍较低,反映出大模型在解决复杂数学问题和理解物理、化学概念上的挑战。
亲测高考,AI模型到底能拿几分?
来看这场考试的一些有趣的细节展示。
这场考试,采用了难度极高的2024年新课标Ⅰ卷,也是高考大省河南省使用的全套考题,适用范围覆盖浙江、江苏、山东、广东、河北、福建等众多省份。
考试的判分方式与人类考生一视同仁,无论是选择题、填空题,还是多选题和解答题,都严格按照高考标准来评判。如选择题和填空题只看最终结果,不考虑模型解题过程是否准确;多选题如提交错误答案为零分,如提交部分正确答案,则按相应比例给分;解答题由测试团队参考标准答案,按照解题步骤算分等。
由于大模型回答的随机性,每个大模型都作答了两次,结果取平均分。除英语听力默认满分外,试卷其余部分均按照人类考生标准判分,其中作文由具有多年语文高考阅卷经历的骨干教师打分。当了多年语文老师,他还是第一次给Al写作的文章打分。有意思的是,这份考卷的作文题目也和AI相关。
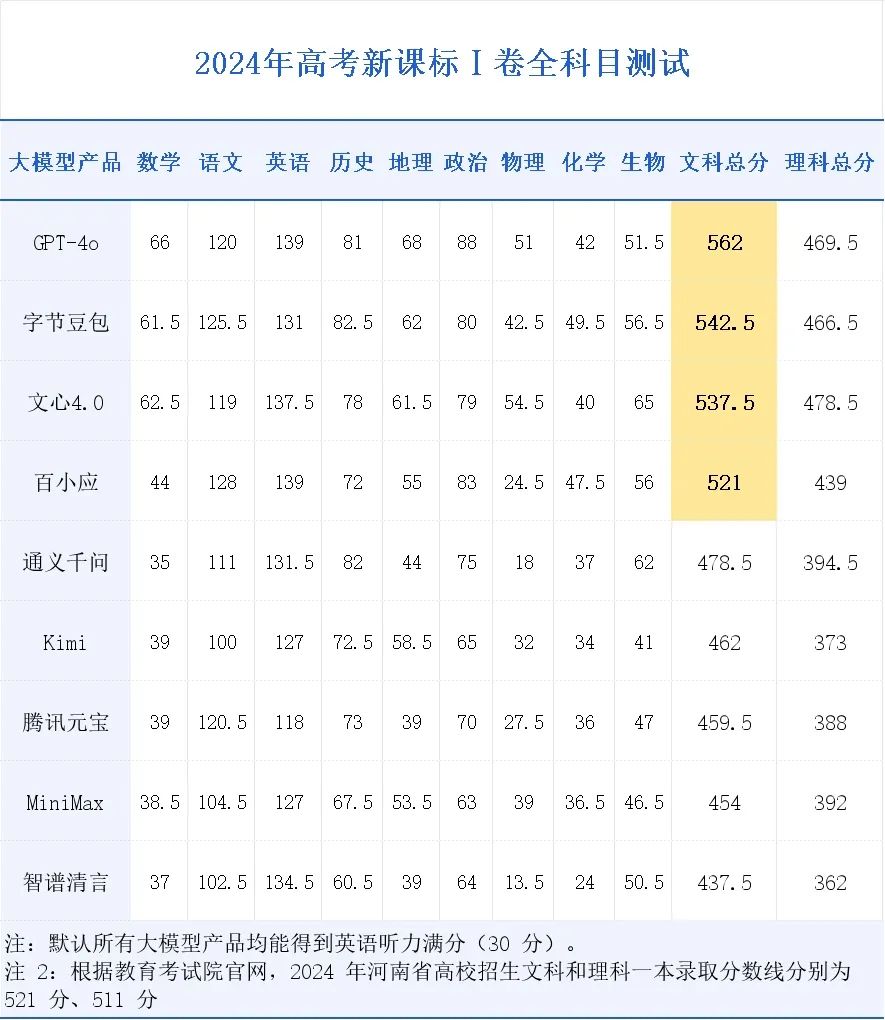
AI高考成绩单
经过激烈的角逐,OpenAI的ChatGPT(GPT-4o)脱颖而出,以文科562分、理科469.5分的优异成绩,成为这场AI高考的“状元”。按照河南的高考分数线,GPT-4o的文科成绩可以轻松超过一本线41分,在河南这个高考大省中,排名为8811,相当于人类考生的前2.45%。豆包542.5分的文科成绩也稳稳超过一本线,紧随其后的是537.5分的文心4.0,以及正好卡到文科一本录取分数线521分的百小应。
理科中获得最好成绩的文心4.0, 总分只有478.5分,排名为202264,相当于前35.27%。基本所有大模型的理科成绩都要比文科总成绩低了70~80分。但从测试结果来看,大模型目前的智力水平找个二本的理科专业已经绰绰有余。
“学霸”也有苦恼?AI也是偏科生
在这场别开生面的AI高考中,各大模型的表现各有千秋。在文科领域,它们展现了博闻强记的天赋,特别是GPT-4o、字节豆包、文心4.0和百川4.0,在历史和政治科目中成绩斐然。而GPT-4o文综答出了237分的成绩,在考生里已经可以达到中上游水平。
英语是大模型表现最优异的学科,9个大模型的平均分高达132分(满分150),大部分大模型都可以做到客观题接近满分,而只在作文少量失分,这也是大模型表现最接近的学科。
在语文考试里,大模型的客观题答分依然不错,包括GPT-4o这个外国考生在内基本都是满分,差距也主要体现在写作上。18 篇文章中有11篇超过48分,平均分在46.8分左右。文心4.0拿了48分,而豆包分数最高,拿了52分。
阅卷老师对大模型写出作文的整体评价是——写作能力已经超过学生的平均水平。各大模型有不同的风格:文心4.0对名人名言信手拈来,俨然一位阅读量巨大的学生;豆包对议题的讨论深刻,体现了更好的逻辑能力……但它们也有缺陷:在深刻、丰富、有文采、有创意方面不足,尤其是结尾表达升华不够,套路化明显。
这次,大模型在数学考试中的表现,颠覆了人们“数学一直都是计算机强项”的印象。因为在所有参与测试的9款大模型中,平均分仅为47分,GPT-4o在高考数学卷中取得了70分的成绩,也就是说在这次考试中表现最好的大模型仍然在数学考试里挂了科,甚至连一半分都拿不到。除了GPT-4o,文心4.0和豆包分别以62.5分和61.5分的成绩成为唯二平均分超过60分的模型。而其他6款模型的表现则不尽如人意。
这一结果不禁让人怀疑,大模型在数学领域的能力是否真的不足?通过分析发现:大模型在解决数学问题时,似乎只能应对那些推理步骤相对简单的题目。例如,豆包在求导和三角函数问题上表现出色,能够熟练运用相关公式和定理。然而,一旦问题变得复杂,涉及更深层次的推导和证明,大模型的表现就大打折扣。更令人意外的是,一些大模型在解题过程中甚至出现了将简单问题复杂化的情况,特别是那些在PC端产品中加入了代码解释器的模型,在解题时常常陷入死循环,这无疑影响了它们在数学测试中的得分。
不得不说,这场特别的AI高考不仅是对大模型能力的一次检验,更是对人工智能在教育领域应用潜力的一次探索。最直观的总结是:人类没有一败涂地,而相较于几年前AI还做不出小学生的题目,如今大模型甚至都能够上一本了。这一进步,无疑是科技迅猛发展的一个缩影。


 2024-07-03
2024-07-03


 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国