

如今,通过制作逼真的视频内容,AI 视频生成工具正在改变设计、营销、娱乐和教育等行业。尤其是 Sora、Gen-3 等文生视频模型,只需要输入几行 prompt 文字,便可以生成逼真、连续、高质量的视频大片。
这一技术在为世界各地创作者带来无数可能性的同时,也为普通大众带来了诸多危害和风险,尤其是在传播虚假信息、宣传、诈骗和网络钓鱼等方面。
因此,如何准确识别 AI 生成的视频,已成为每一个人都需要关心的问题。
日前,哥伦比亚大学杨俊锋(Junfeng Yang)教授团队便开发了一种名为 DIVID(DIffusion-generated VIdeo Detector)的文生视频检测工具,对于由 SORA、Gen-2 和 Pika 等模型生成的视频,检测准确率达到了 93.7%。
相关研究论文(包含开源代码和数据集)已于上月在西雅图举行的计算机视觉与模式识别会议(CVPR)上展示。

DIVID 是如何炼成的?
现有的 Deepfake 检测器在识别 GAN 生成的样本方面表现出色,但在检测扩散模型生成的视频方面鲁棒性不足。
在这项工作中,研究团队通过 DIVID 这一新工具来检测由 AI 生成的视频。据介绍,DIVID 基于该团队今年早些时候发布的成果——Raidar,其通过分析文本本身来检测由 AI 生成的文本,而无需访问大语言模型(LLM)的内部运作。
Raidar 使用 LLM 来重述或修改给定文本,然后测量系统对该文本的编辑次数。编辑次数越多,意味着文本更可能是由人类撰写;编辑次数越少,意味着文本更可能是机器生成的。
他们使用相同的概念开发了 DIVID。DIVID 通过重构视频并将新重构的视频与原始视频进行对比来工作。它使用 DIRE 值来检测扩散生成的视频,因为该方法基于这样一个假设:由扩散模型生成的重构图像应彼此非常相似,因为它们是从扩散过程分布中采样的。如果存在显著的变化,原始视频可能是人类生成的,如果没有,则可能是 AI 生成的。
图 | DIVID 的检测流程。在步骤 1 中,给定一系列视频帧,研究团队首先使用扩散模型生成每个帧的重建版本。然后通过重建帧和其对应的输入帧计算 DIRE 值;在步骤2中,基于 DIRE 值序列和原始 RGB 帧训练 CNN+LSTM 检测器。
该框架基于这样一个理念:AI 生成工具根据大数据集的统计分布创建内容,导致视频帧中的像素强度分布、纹理模式和噪声特征等“统计均值”内容,以及帧间不自然变化的微小不一致性或更可能出现在扩散生成视频中的异常模式。
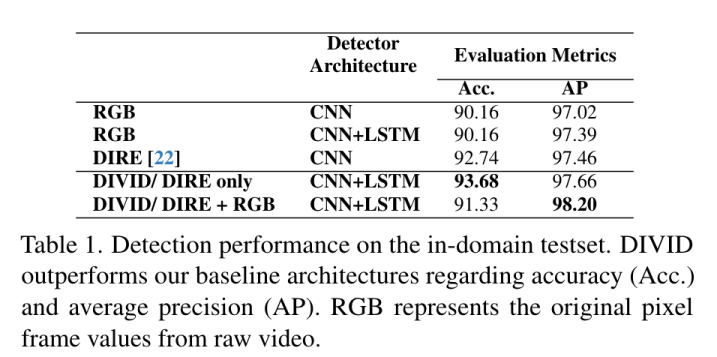
图 | 在域内测试集上的检测性能。DIVID 在准确率(Acc.)和平均精度(AP)方面优于基线架构。RGB 表示原始视频中的像素帧值。
相比之下,人类创作的视频表现出个性化,偏离统计常态。DIVID 在其基准数据集中对 Stable Vision Diffusion、Sora、Pika 和 Gen-2 生成的视频实现了高达 93.7% 的检测准确率。
未来展望
目前,DIVID 是一个命令行工具,用于分析视频并输出其是由 AI 还是人类生成的,且仅供开发者使用。研究人员指出,他们的技术有潜力作为插件集成到 Zoom 中,以实时检测深度伪造电话。团队还考虑开发一个网站或浏览器插件,使 DIVID 对普通用户可用。
研究人员目前正在改进 DIVID 的框架,以便处理来自开源视频生成工具的不同类型的合成视频。他们还在使用 DIVID 收集视频以扩展 DIVID 数据集。
“我们的框架在检测 AI 生成内容方面取得了重大进展,” 该论文的作者之一、蔡昀芸(Yun-Yun Tsai)博士说道。“有太多不法分子在使用 AI 生成视频,关键是要阻止他们并保护社会。”
参考链接:
https://arxiv.org/abs/2406.09601
https://techxplore.com/news/2024-06-tool-ai-generated-videos-accuracy.html


 2024-07-08
2024-07-08


 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国