

图片和视频生成是近年来人工智能领域备受关注的研究热点。其中,基于用户文本提示词生成图片和视频的技术,有效构建了用户意图与视觉内容之间的桥梁。然而,此类生成技术的模型通常具备海量参数,其带来的高计算和存储成本远超单个用户设备的能力范围,因此依托移动通信网络的云边端协同计算架构已成为解决这一问题的主流选择之一。本文将介绍基于文本提示词生成图片与视频模型的发展历程、核心架构及其最新技术进展,并进一步分析生成式AI应用对通信网络的需求和挑战。
1、图片生成模型
文生图任务,即生成文本提示词指定内容的图片,是图片生成的关键任务之一。该任务为用户提供了一种直接的、基于自然语言的视觉创作方式,构建了用户意图与图片之间的桥梁。因此,文生图任务的相关模型常被作为图片修复、编辑等其他生成任务的骨干框架。此外,近年来文生图技术迅猛发展,各类模型不断突破。
目前,支撑文生图任务的模型包括:1)基于生成对抗网络(GAN)的模型:例如2019年提出的ControlGAN等;2)基于自回归的模型:例如2021年问世的DALL·E 等;3)基于扩散模型(Diffusion Models)的架构等。扩散模型近年来受到极大关注[1],2022年出现的GLIDE等均为基于扩散模型的方案。扩散模型通过逐步反向去噪的方式生成图片,能够平衡生成速度和细节保真度,弥补了GAN在训练稳定性等方面的不足,解决了自回归模型存在的错误积累、高额计算开销等问题。
下面介绍两个知名的基于扩散模型的文生图方案:Stable Diffusion和DALL·E 2。
Stable Diffusion于2022年问世,是基于扩散模型的开源代表作之一。其架构如图1所示。在训练过程中,首先使用预训练的自编码器将用于训练的图片映射到潜空间,从而将图片从高维空间压缩到一个低维表示空间,便于处理和计算。此后,逐步向训练图片的潜空间表达添加噪声,训练获得能去除噪声,恢复图片的去噪网络。为了生成与文本提示词匹配的图片,Stable Diffusion使用基于Transformer的文本编码器,将提示词转化为文本嵌入(text embedding),将其在训练过程中作为条件信号,与图片的潜空间表达一起传递至去噪网络。在Stable Diffusion的采样过程中,首先对文本提示词进行编码获得嵌入。此后,从一个噪声图片的潜空间表达开始,基于文本嵌入与训练得到的去噪网络,逐步生成与提示词匹配的潜空间表达,并采用预训练的解码器得到生成的图片。
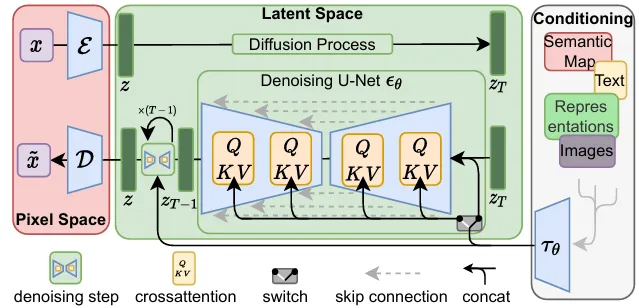
图1 Stable Diffusion的模型架构[2]
目前,更新版本的Stable Diffusion相继推出,包括 Stable Diffusion3和3.5等。在版本特性上,Stable Diffusion 3 结合了扩散Transformer架构与流匹配(flow matching)技术,进一步提升了生成图片的准确性和质量。Stable Diffusion 3.5版本在Transformer模块中引入Query-Key Normalization,以稳定模型的训练过程,并简化后续的微调和开发流程。
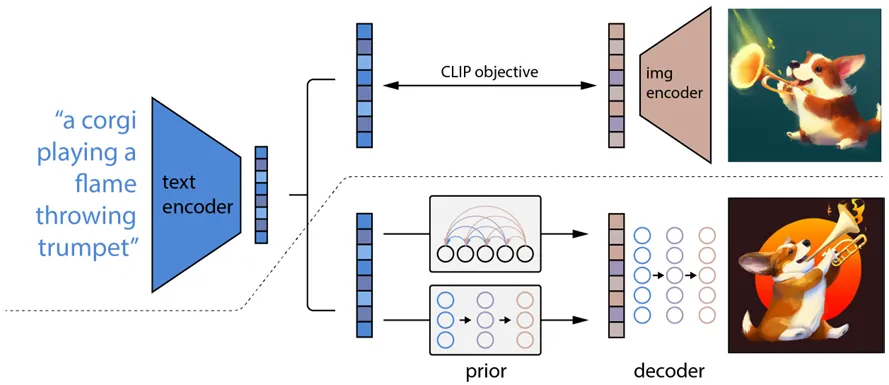
图2 DALL·E 2的模型架构[3]
DALL·E 2 [3]由 OpenAI提出,是文生图领域的重要突破之一。在训练过程中,DALL·E首先训练CLIP(Contrastive Language-Image Pre-training)模型,获得使内容匹配的文本和图片的编码具备高余弦相似度的文本和图片编码器 (图2虚线上内容所示)。此后,训练两个扩散模型使其分别完成文本编码到匹配的图片编码的映射(图2中prior模块),和以图片编码为条件生成相关图片的任务(图2中decoder模块)。在图片生成过程中,DALL·E 2首先使用训练的文本编码器对文本提示词进行编码,并采用扩散模型基于提示词编码获得图片编码,并最终生成图片。与Stable Diffusion不同的是,在DALL·E 2生成图片的过程中,文本提示词编码是生成任务的起点,而Stable Diffusion中生成任务的起点则为噪声图片的潜空间表达。同时,在Stable Diffusion中,文本提示词编码仅作为条件信号,对生成的过程进行约束。
2023年8月,Open AI发布DALL·E 3。该版本与GPT-4深度集成,GPT-4的自然语言理解能力使其能更高效地解析文本提示词,增强了图片生成的精确度。
2、视频生成模型
视频生成模型作为生成式AI的重要分支,对比单帧图像生成,计算量成倍增加,对硬件资源提出了更高的挑战。随着算法优化、数据多样性提升以及硬件技术的进步,近年来在深度学习的推动下,视频生成模型正逐步向更高效、更精准的方向发展,并向实时化、多模态化演进。在未来,视频生成将不仅用于日常娱乐,在6G通信、XR等领域的应用潜力也正在被广泛发掘。
视频生成技术的发展经历了从早期模型到现代更复杂架构的重要跃升。MoCoGAN(Motion-Content GAN)、深度伪造(Deepfakes)等基于GAN的视频生成的问世标志着视频生成模型的起步。自2022年扩散模型在计算机视觉领域的引入以来,视频生成技术迎来了革命性的突破。OpenAI和Meta等公司相继推出了如Make-A-Video和Imagen Video等基于3D UNet的扩散模型。2023年,Runway、Stability AI分别发布自己的支持模态转换的视频模型,为多模态打下基础。2024年,OpenAI发布基于Diffusion Transformer (DiT) 的Sora模型,实现了媲美电影级别的视频生成;Meta则推出MovieGen,集成视频生成、个性化生成、精准编辑和音频生成等功能,在真实性和美观性上取得突破。同年,多款基于DiT的开源模型如CogVideoX、Mochi1和LTX Video相继问世,为大众提供了丰富的视频生成工具。
视频生成模型在技术原理上与图片生成模型一脉相承,但其独特之处在于对时空维度的联合建模。由于视频由连续的图片帧组成,模型同时处理空间信息(图片的像素分布)和时间信息(连续帧之间的动态关联),不仅需要生成单帧的高质量视觉内容,还要在多个帧之间捕捉动态变化和逻辑一致性,从而超越图片生成仅关注空间特征的局限。
目前主流的一些文生视频模型的生成流程可以总结为:通过文本编码器提取语义信息,结合时空VAE编码器对视频的时空特征进行潜变量建模,并利用结合了扩散模型机制的Transformer的去噪生成过程逐步优化潜空间里的张量,最后利用时空VAE解码器转换回动态一致且高质量的视频内容。图3展示了当今高性能的视频生成模型MovieGen的整体架构,包含文本编码器、TAE(Temporal Autoencoder,一种时空VAE)和Transformer模块。
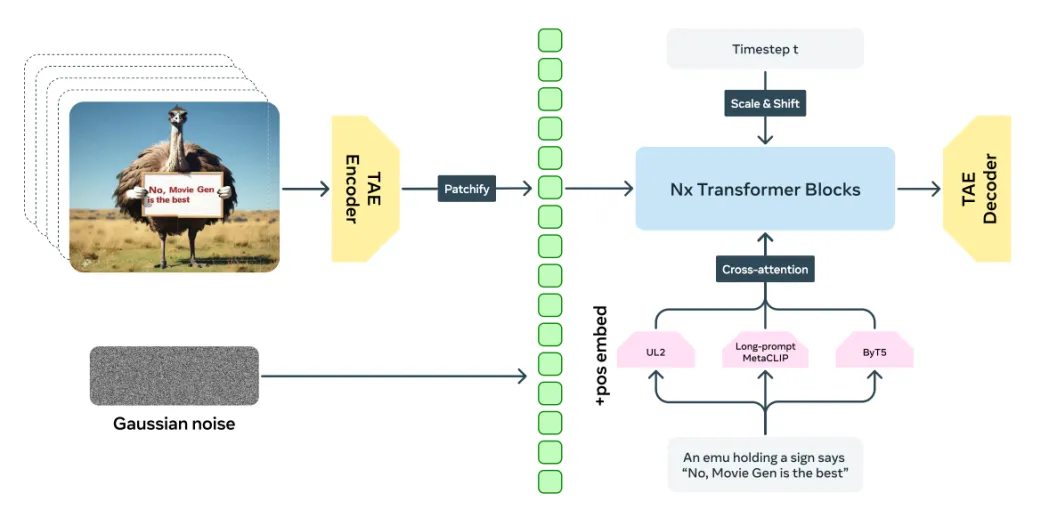
图3 MovieGen的整体架构图[4]
下面介绍当前典型的文生视频模型的技术架构所包含的关键模块:
①文本编码器(Text Encoder)
用户输入一个描述视频内容的文本,文本编码器(Text Encoder)能够提取文本的语义信息并转化为适合模型处理的高维向量。常见的文本编码器通常基于预训练语言模型构建,能够高效提取语言特征并生成嵌入表示。
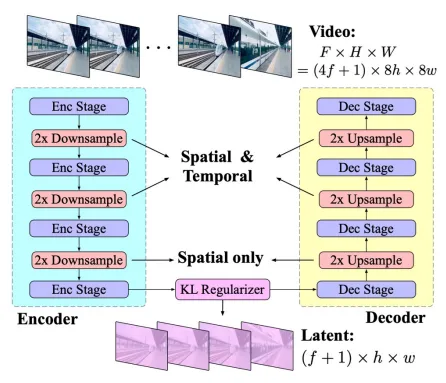
图4 CogVideoX使用的3D Causal VAE(一种时空VAE的变体)架构[5]
②时空变分自编码器(Spatio-Temporal Variational Autoencoder)
时空变分自编码器(时空VAE)是传统VAE在视频场景下的扩展,经常在不同模型中根据变体拥有不同的命名。图4展示了开源模型CogVideoX使用的一种时空VAE架构。训练时通过对视频帧序列的空间与时间特性进行潜变量建模,时空VAE能够将高维视频数据压缩映射到低维潜空间,将数据表示为一种简化固定大小的张量,从而便于后续DiT生成。在生成阶段,其解码器模块负责在去噪阶段结束后,将潜变量空间的表示转化为完整的、高质量的视频帧序列。[4][5]
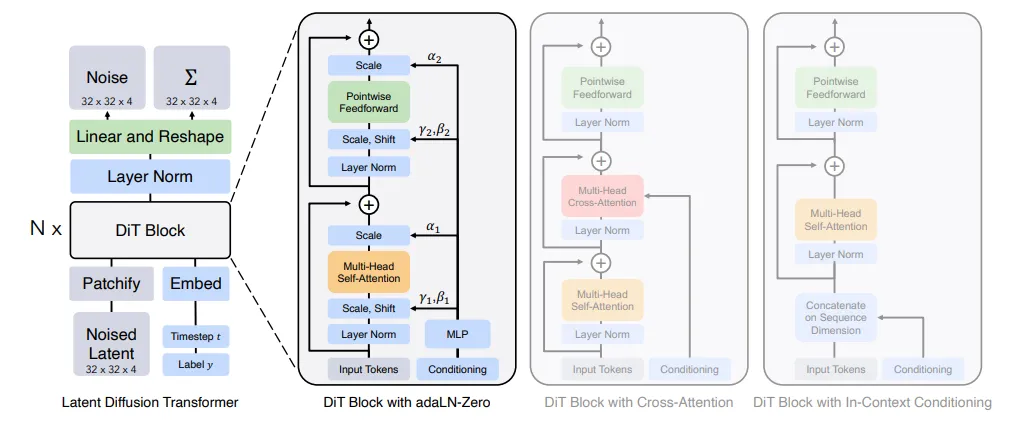
图5 Diffusion Transformers (DiT) 的架构[6]
③Diffusion Transformer(DiT)
DiT是当前视频生成领域的一种先进架构,将扩散模型与Transformer架构相结合,如图5所示。[6]与传统基于UNet的扩散模型(如LDPM)不同,DiT以Transformer为核心框架,通过自注意力机制(Self-Attention)高效提取和表示输入特征。在生成阶段,DiT利用扩散模型的逐步去噪生成策略,逼近目标分布,经过多次迭代优化生成高质量的视频样本。在用于视频生成的场景中,DiT进一步集成了时空注意力机制(S-T Attention),相较于传统的Attention机制,引入了一个对于时间维度的处理,使得DiT能够同时捕获视频的时序动态和空间细节。通过逐步优化,结合了条件嵌入(如时间步)和自适应归一化(adaLN),模型在空间分辨率、时间一致性和生成效率方面均表现出色。
视频生成技术从早期的探索阶段逐渐迈向成熟。在AI技术的持续突破下,可以预见,未来的视频生成技术将变得更加智能化、高效化,并展现出更丰富的多样性。此外,随着5G/6G通信网络和云计算等技术的快速发展,视频生成技术的应用范围将不断拓宽,例如,云端视频生成为用户提供强大的支持,典型应用包括AI视频生成创作平台;此外,依托边缘计算技术的实时互动功能正在改变用户体验,如视频生成赋能的XR业务动态渲染。与此同时,更具创意的应用场景也在涌现,例如实时个性化视频推送服务、通过视频生成实现实时视频通信优化,以及智能虚拟客服与助理的动态视频交互等,为各个领域带来广泛的创新,同时也将为我们的生活增添更多便捷与乐趣。
3、图片和视频生成应用对移动通信网络的影响
随着图片和视频生成技术的成熟,越来越多的移动终端应用开始采用生成式模型来提供新型的个性化娱乐体验。例如,视频聊天工具可以利用图片和视频生成模型为用户提供个性化的视觉效果;拍照应用则可以通过图片生成模型实现对照片的高度自定义编辑;短视频平台能够引入视频生成模型,降低内容创作门槛;智能个人助理则能通过图片和视频生成技术将用户的创意具象化。图6展示了一种可能的新型视频应用运行方式。应用视频服务器不光能够根据用户需求生成对应的图片和视频,还可以将用户创作的视频共享到应用数据库中,作为其他用户的视频素材。应用通过了解用户的喜好倾向,将共享的视频素材经过云-端推理引擎的二次加工,协作生成定制化图片视频,满足用户个性化的观看体验。
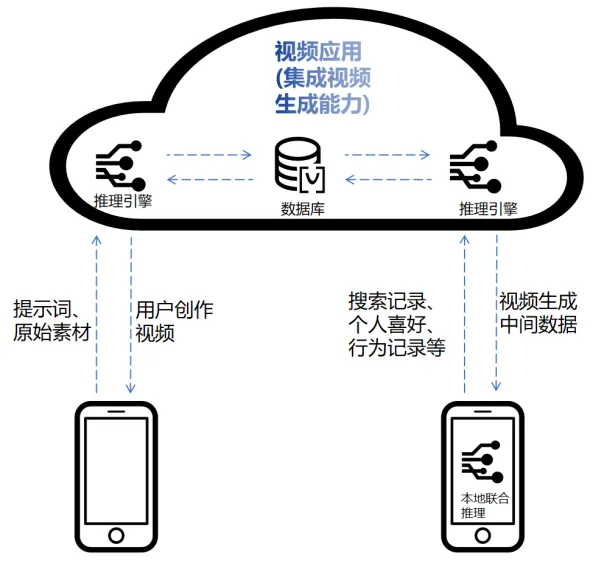
图6 利用生成式模型的新型视频应用
这类应用的发展不仅改变了人们的数字娱乐方式,也对现有的移动通信网络提出了新的要求。生成式模型在实际运行中的不同环节,其数据传输的特性需求也不同,主要包括以下几类:
①提示词和原始素材,如高分辨率图像、视频帧或多模态数据(如音频、文本)的传输。这些数据以上行流量为主,输入数据结构多样,通常带宽需求较小但流量产生难以预测;
②中间数据,在生成式AI模型的云-边-端分布式协作计算的过程中,可能需要频繁传输大量中间数据,如中间生成结果如特征向量、模型更新的权重和梯度数据等。这些数据具有高维、动态变化的特征,其丢包率容忍度根据具体任务的不同差异大,但计算过程中流量产生有规律性;
③最终生成结果,如高分辨率的图像、视频片段和视频流的传输。这些数据以下行流量为主,体积较大,对网络的带宽、延迟和抖动要求最高。
随着集成生成式模型的新型应用的普及,其传输数据规模也将随之爆发。为了高效传输上述数据类型,并满足越来越低的时延需求和越来越高的体验需求,未来的移动通信网络需要进一步提升网业协同的能力,使应用能够更好地感知网络发生的变化,网络更好理解传输的内容。为此,需要提升网络状态信息开放能力以及差异化的数据传输保障能力。首先,为进一步提升业务对网络的适配能力,网络需要更动态、实时、丰富得向生成式应用开放状态信息,以允许应用实时感知网络状态(如带宽、延迟、拥塞情况等),从而实时调整任务的计算资源分配,数据压缩算法和数据传输策略以满足不同传输情况下用户的流畅体验。其次,多模态生成数据的传输需要更差异化保障,以满足不同的延迟、可靠性需求。例如,在视频生成任务中,生成的帧序列可能以流的形式分批传输并标记帧属性和依赖关系,这要求网络支持高效的流式数据调度管理和多模态协同的传输优化方式。允许对不同类型的数据类型提出更多维度的传输需求,通过更差异化的传输策略(如调度优先级、重传配置或专用通道)提高关键数据的传输效率。
此外,由于移动设备在成本控制、能耗限制以及散热管理等方面的考虑,其计算能力往往不足以支撑高质量生成式AI模型的本地运行。因此,未来的解决方案需依赖于移动设备与网络之间的高效协同计算,以保证生成质量并控制生成延迟。这对移动通信网络提出了进一步的需求:
①边缘计算能力增强,网络需要在边缘节点部署强大的计算能力,并通过分布式计算框架,动态调度计算任务至最优位置执行;
②通信与计算的一体化调度:通过联合调度空口资源和计算资源,实现通信链路和计算节点的协同优化。例如,动态分配算力以满足生成任务的峰值需求,并确保低延迟的反馈循环;
③模型分割与传输优化:针对生成式模型规模大的特点,可以探索模型分割技术,将模型拆分为多个模块,在终端与边缘节点之间分布运行。此过程中,如何高效传输模型分片和运算中间结果数据,是优化的核心要素之一。
4、结语
随着图片和视频生成技术的不断进步及其广泛应用,它们正逐步演变为未来主流的业务形态。这种业务也对支撑其运行的移动通信网络提出了新的挑战和需求。为了确保用户体验,网络需要高效传输原始素材、中间结果、最终生成结果等各种数据,并适应生成式AI应用特有的流量特征。此外,考虑到移动设备的计算限制,网络需增强边缘计算能力、实现通信与计算的一体化调度以及优化模型分割与传输策略,以支持云边端协同计算架构。
[参考文献]
[1]A. Nichol, P. Dhariwal et al., Glide: Towards photorealistic image generation and editing with text-guided diffusion models, ICML (2022).
[2]R. Rombach, A. Blattmann, D. Lorenz, P. Esser, B. Ommer, High-resolution image synthesis with latent diffusion models, in: Proceedings of the IEEE CVPR, 2022, pp. 10684–10695.
[3]A. Ramesh, P. Dhariwal, A. Nichol, C. Chu, M. Chen, Hierarchical textconditional image generation with clip latents, arXiv:2204.06125 (2022).
[4]Adam Polyak, Amit Zohar, et al. Movie Gen: A Cast of Media Foundation Models, arXiv:2410.13720.
[5]Zhuoyi Yang, Jiayan Teng, et al. CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer, arXiv:2408.06072.
[6]William Peebles, Saining Xie. Scalable Diffusion Models with Transformers, arXiv:2212.09748.
[7]Wilson Yan, Yunzhi Zhang, Pieter Abbeel, Aravind Srinivas. VideoGPT: Video Generation using VQ-VAE and Transformers, arXiv:2104.10157.
作者:王乐涵、任逸 、陈子奇、孙奇
单位:中国移动研究院



 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国