

数据几乎无处不在,它帮助我们了解世界、预测未来,甚至解答一些人类最深奥的谜题。尤其在生物信息学的领域,大量的生物学数据被用来解码基因、研究蛋白质、探索细胞行为等。
这些数据大多数是通过先进的仪器和技术手段采集的,但不可避免地,这些数据也会包含一些错误、缺失或者不一致的地方。如果我们不解决这些问题,数据就会变得没有意义,甚至会导致错误的科学结论。这个时候,**“数据清洗”**就显得尤为重要了。
“数据清洗”(data-cleaning),顾名思义,就是将原始数据中的不正确、不完整、重复或不一致的部分进行修正,最终获得一组可靠、整洁的数据。在生物信息学中,这一步尤为关键。因为这些数据关系到我们对生物现象的理解,直接影响到后续的分析和研究结果。
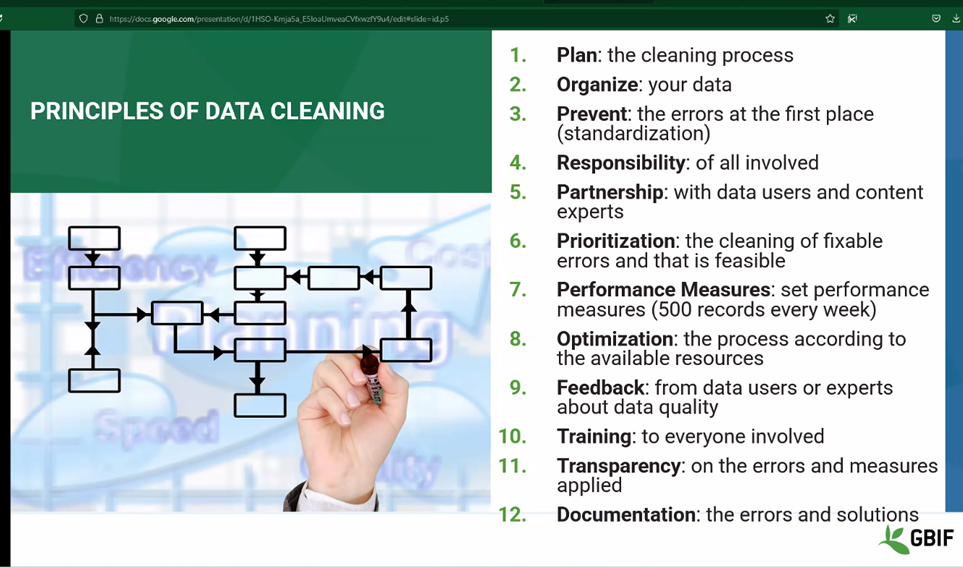
上图来源:全球生物多样性信息平台(GBIF)亚洲数据动员会
你可以想象一下,如果我们在进行基因研究时,某个重要基因的序列数据缺失了,或者错误地记录了,最后分析出来的结果就可能完全不准确,这样的错误很可能会带来巨大的科研损失。再比如,实验过程中出现了重复的数据,或者由于仪器故障,某些数据记录不完整,这些问题都会在生物信息学的研究中造成困扰,影响研究的可信度。所以,数据清洗不仅仅是数据处理的第一步,它还是确保科学研究质量的必要步骤。

科科斯岛(Cocos Island),全称可可斯岛国家公园(Isla del Coco National Park),是位于东太平洋哥斯达黎加西南约550公里处的一座火山岛,1997年被联合国教科文组织列为世界自然遗产。该岛面积仅24平方公里,却是全球最重要的海洋生物多样性热点之一,被誉为“鲨鱼的王国”和“潜水者的圣地”。上图是潜水所摄。事实上,大量公民科学家的观测数据,已经成为生物多样性信息学的重要数据来源。©赵宇 | 绿会融媒·“海洋与湿地”(图文无关)
换句话说,数据清洗,如同整理房间,目的是让数据变得井然有序,机器才能更好地理解和利用。原始数据往往混杂着各种问题:缺失值、重复值、格式不统一、错误值等等。这些“脏数据”会干扰机器的判断,导致分析结果不准确,甚至产生错误的结论。数据清洗就是通过一系列技术手段,将这些“脏数据”一一剔除或修正,让数据变得干净、规范,机器才能更好地读取、处理和分析,从而发挥数据的价值。
在生物信息学的研究中,数据清洗面对的主要问题通常包括缺失数据(Missing Data)、重复数据(Duplicate Data)、不一致数据(Inconsistent Data)、错误数据(Erroneous Data)和离群值(Outliers)等。
先来说说,缺失数据。“缺失数据”是最常见的问题之一。举个例子,可能在基因测序时,由于技术的限制或者操作问题,部分基因的序列信息没能完整记录下来。这时候,我们需要通过一些方法来补充这些缺失数据。比如,使用其他相似数据来推测缺失部分,或者简单地用数据集的平均值或者中位数来填补空白。
另外,重复数据也是常见的问题。在实验过程中,有时由于操作不当或者数据记录的重复,某些信息被多次记录。这不仅占用了存储空间,还会影响后续分析的准确性。去重是数据清洗中不可或缺的一部分,尤其是在处理大型数据集时,去除重复数据可以显著提高数据的质量。
不一致的数据,也常常给研究人员带来困扰。尤其是当数据来自多个不同的来源时,格式或单位的不一致性是一个常见问题。例如,基因的名称在不同的数据库中可能会有所不同,或者实验中使用的单位不同,这样的不一致性需要统一和标准化,才能确保后续分析的准确性。

上图来源:全球生物多样性信息平台(GBIF)亚洲数据动员会
更复杂的问题是错误数据。错误数据可能是由于设备故障、人为操作失误或其他因素导致的。比如,在基因组测序过程中,仪器可能会出现读取错误,从而产生错误的基因序列。如果不及时修正,这样的错误数据会影响整个研究的结论。因此,发现并修正这些错误是数据清洗中的一项重要任务。
另外,离群值也是一个必须处理的问题。“离群值”是指那些远离其他数据点的异常值。在生物信息学中,离群值有时可能代表某些重要的生物学现象,但有时它也可能是由于设备故障或操作不当造成的。离群值的处理通常需要更加细致的分析,如果确定它们是无关紧要的错误数据,可以将其删除。如果它们可能是有意义的现象,研究人员则需要进一步分析它们的潜在价值。
全球生物多样性信息平台(GBIF)是一个非常重要的生物多样性信息学基础设施、数据平台,专门收集和共享关于全球物种分布等各种生物学数据。你可以想象,这些数据来自世界各地的研究人员和机构,数据的格式和质量可能五花八门。有的可能是填写不完整,有的可能在录入时出现了小错误,甚至有些数据是重复的。为了确保这些数据准确可靠,GBIF必须做大量的数据清洗工作。所以首先,在针对这类处理的处理上需要明确一个清晰的清洗计划,决定哪些数据问题是最迫切需要解决的。比方说,有些数据缺失,可以补充;而有些数据可能格式错乱,必须先进行规范化。这个过程的一个重要原则就是优先处理那些“可修正”的错误,也就是那些最容易解决的问题,这样能够让数据尽快变得更清晰。
接下来,来看看在技术层面上如何进行数据清洗。在数据清洗过程中,GBIF会重点关注数据的完整性、类型、格式等方面的技术性错误。例如,日期字段可能会出现格式问题,像“01/01/2010”或者“01/Jan/10”,这些都需要统一格式,以确保数据的一致性。同时,GBIF还会检查是否所有的字段都有填写,避免出现某些数据空白的情况。还有,比如在数据导出时,有时会因为操作失误导致列的位置发生变化,GBIF也会自动检测并修正这些“小插曲”。这些技术性检查大多可以通过自动化的方式进行,所以GBIF可以高效地清理大量数据,确保数据在格式和结构上没有问题。
此外,数据清洗不仅仅是处理技术错误,还要考虑到数据的一致性问题。比如,GBIF会检查物种名称是否符合生物学命名规则,确保没有错误的物种分类。另外,GBIF也会检查数据中的地理坐标,确保这些数据在地理上是合理的。比如,如果某个物种的分布范围本来应该是在某个地区,但它的数据却显示在完全不同的地方,这可能就是个错误。还有一些数据可能看起来很“精准”,但是在早期没有GPS的时代,采集的数据就不可能这么准确,所以GBIF会特别注意这些问题。GBIF通过这些细致的检查,确保每一条数据的价值和清洁度,从而为全球生物多样性研究提供可靠的科学数据的支持。通过这些细致入微的清洗,GBIF为全球科研人员提供了一份“干净”的数据大餐。
数据清洗****的过程,并不是简单的删除错误或者填补空白,实际上它需要结合专业知识、技术手段和一定的判断能力。对于生物信息学的研究人员来说,除了要掌握数据清洗的常规方法外,还要有足够的生物学背景知识,才能在面对复杂的生物数据时做出正确的判断。比如,对于基因数据的错误序列,研究人员不仅需要知道怎样修正数据,还需要理解基因组学的基本原理,才能确保修正后的数据依然符合生物学的规律。
数据清洗的技术手段也在不断发展,现代的生物信息学工具和算法可以帮助研究人员更加高效、准确地完成这一过程。例如,一些基于机器学习的算法可以自动识别和修正数据中的错误,或者通过统计模型填补缺失数据,这些技术极大地提升了数据清洗的效率和精度。
虽然数据清洗看起来是一个繁琐且技术性强的过程,但它对于生物信息学的研究是至关重要的。通过数据清洗,我们可以最大限度地保证数据的准确性和完整性,进而为后续的分析提供可靠的基础。毕竟,数据只是原材料,只有经过清洗和处理,它才能真正发挥价值。如果没有做好数据清洗,后续的分析和研究结果都可能受到影响,甚至会得出错误的结论。

这张图片中心,是儒艮双胞胎在母兽两侧畅游。周围有成年的儒艮守护。这也反映了儒艮的社交群体活动模式。这类迁徙物种的监测数据,是重要的生物多样性信息学数据来源。图源:卡塔尔海湾地区鲸鲨保护中心(RWSCC)| 供图:王敏幹(John MK Wong)(图文无关)
以上是“海洋与湿地”(OceanWetlands)小编在近日参加全球生物多样性信息平台(GBIF)亚洲数据动员会之后的一篇小作业。不难理解,“数据清洗”在生物信息学中扮演着至关重要的角色。它帮助我们从一堆“脏乱”的数据中筛选出“干净”的数据,为后续的分析和研究打下坚实的基础。尽管数据清洗需要耗费一定的时间和精力,但它却是确保科研结果可靠性的必要步骤。如果能够做好数据清洗,我们就能够更加精准地理解生命的奥秘,推动生物学研究的进步。
(注:1.本文仅代表资讯,不代表平台观点。欢迎留言、讨论。2.通常物种的拉丁学名一般以斜体显示;但是因本平台的文章被拷贝到外部平台时经常出现斜体内容自动丢失的情况,故而未作斜体设置。特此说明。)
文 | 王昆山编辑 | 绿茵排版 | 绿叶
参考资料略


 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国